
Citizen-Generated Data: Data by people, for people
Investments in a rich data ecosystem that supports citizen-generated data alongside official data sources empowers marginalized groups, provides a holistic understanding of marginalization, and supports inclusive decision-making to ensure that no one is left behind in SDG implementation.
A key challenge in following through on the 2030 Agenda’s principle to address the needs of those who have been left behind is that their perspectives and values are not adequately reflected in official data collected by national statistical offices. People who have been left behind also suffer from data marginalization, with some groups being outright invisible in national statistics. Citizen-generated data can complement official data and provide important context for decision-makers. Investments in a rich data ecosystem that supports citizen-generated data alongside official data sources empower marginalized groups, provide a holistic understanding of marginalization, and support inclusive decision making to ensure that no one is left behind in SDG implementation.
What is citizen-generated data?
Put simply, citizen-generated data is “data generated by people, for people,” meaning that the individuals who stand to benefit from data collection are directly involved in the design, collection, analysis, and use of data that describes them. The CIVICUS DataShift program defines citizen-generated data as data that “people or their organizations produce to directly monitor, demand, or drive change on issues that affect them. It is actively given by citizens, providing direct representations of their perspectives and an alternative to datasets collected by governments or international institutions.”
Citizen-generated data includes a wide variety of approaches and methods. Depending on the purpose at hand, the term is used interchangeably with concepts like citizen science, community-driven data, or participatory data. All of these terms represent people taking an active role in one or several stages of the data value chain, from identifying questions and objectives to developing methods, collecting data, and analyzing and disseminating the results.
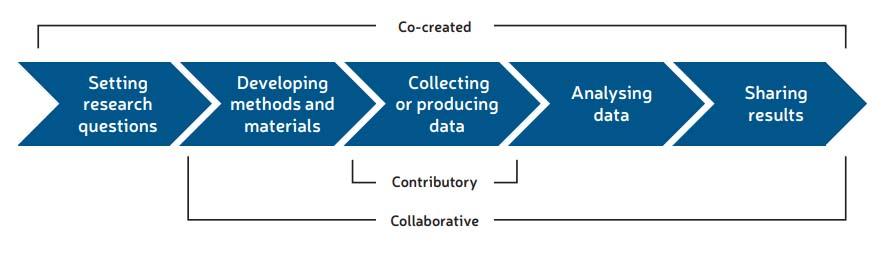
In their 2012 study, Shirk et al. distinguish between contributory, collaborative, and co-created data depending on the extent of citizen engagement at different stages. Other forms of partial engagement are also possible; for example, consultations to determine the analysis and interpretation of data sets collected by official sources provide people with the opportunity to influence and correct the messages that are transported through the data in question.
Why is citizen-generated data needed?
The UN University Institute on Computing and Society identifies five types of data marginalization that can exclude the voices of marginalized groups in data collection and decision making. Like the factors causing marginalization, the factors of data exclusion can intersect so that a group's voice is missing from official data sets for multiple reasons.
| Unknown voices | Population groups that are unknown to the institutions collecting data. These groups include isolated and untouched communities; modern-day enslaved people, such as victims of forced labour, human trafficking, and sex slaves; and individuals concealing themselves because they are illegal immigrants, afraid of losing assistance, or involved in criminal activities. |
| Silent voices | People unable to participate in data collection or other activities through which their concerns could be heard. While their objective well-being can be documented, their lived experience remains hidden. Silent voices include people who are weak and vulnerable because of socio-economic status or old age, persons with disabilities, and children. |
| Muted voices | Population groups that are marginalized because of social norms, societal values, and social practices. Information about their well-being is being suppressed through structural means like missing questions and categories in questionnaires or active exclusion from social life. The muted voices include members of the LGBTQS2S+ community, women, stigmatized groups facing prejudice and racism, and low-skilled migrant workers and refugees. |
| Unheard voices | Population groups that are excluded in sampling approaches and data collection efforts because they are hard to reach or inconvenient to involve. Unheard voices include people that are illiterate, have no permanent address, lack digital connection, experience language limitations, or do not participate in activities that are used to generate data, such as cellphone use, banking, or filing tax returns. |
| Ignored voices | Individuals whose concerns are lost due to shortcomings of statistical methods, such as aggregation bias or ecological fallacy—assuming that correlations at the aggregate level are true for individuals—leading to the well-being of those individuals being disregarded or misrepresented. |
Figure 2: Data marginalization (Source: UN University Institute on Computing and Society, 2018)
Data is never perfect. Data gaps and the challenges of adequately describing people’s needs, perspectives, and values are more prevalent for marginalized people than other groups, partly because marginalization results from a complex interplay of many factors, some of which also affect data collection (Figure 2).
The causes of data exclusion vary between countries depending on their economic status and culture, but it is fair to say that marginalized groups in all countries struggle to make their voices heard. Decision-makers, on the other hand, lack adequate information to design effective interventions. Data marginalization of any kind means that even well-intentioned strategies and programs risk being ineffective at best and creating adverse outcomes, such as inflicting harm or reinforcing stigma, at worst.
Citizen-generated data in action
Citizen-generated data comprises many methods and approaches, as the following examples show. In each case, data was collected for a specific purpose that determined the process, how people engaged, and ultimately the outcome achieved.
-
In Canada, many communities participate in Everyone Counts, a community-level survey of sheltered and unsheltered homelessness conducted on a specific day (point-in-time), also referred to as a Street Census. Data collection is conducted by trained volunteers from the community using a toolkit and standard provided by Employment and Social Development Canada as part of Canada’s Homelessness Strategy. The data collected is used to determine community needs for shelter and housing and directly connect with the people affected. In Winnipeg, for example, a Street Census has been conducted in 2015, 2018, 2021 and 2022. The End Homelessness Winnipeg Initiative uses Street Census data to track the progress of its 10-year plan to end homelessness in the city. Some of the data is also made available on Peg, Winnipeg’s community indicator dashboard.
-
Making Voices Heard and Count is a global initiative by the International Civil Society Center that promotes the use of community-driven data to give a voice and agency to marginalized groups that are at risk of being excluded from official data. National coalitions of civil society organizations and other actors use various community-driven methods to collect data on the most marginalized groups. In Nepal, for example, a local coalition uses community scorecards to collect data on young women and girls to assess gender equality. In India, civil society organizations trained thousands of volunteers to collect community data on 20 marginalized groups across the country.
-
Open street mapping allows citizens to annotate maps with data on physical features like buildings and infrastructure, as well as data on the incidence of violence, damage resulting from extreme weather events, or the quality of services available. The Humanitarian Open Street Map team supports open mapping to improve disaster management and reduce risks. The IDEAMAPS (Integrated DEprived Area MAPing) Network facilitates the combination of data from geospatial, statistical, and community-driven sources to improve information about informal “slum” dwellings in many counties. In Canada, Statistics Canada has used open mapping to crowdsource data collection about building footprints for the Open Database of Buildings to fill a critical data gap on housing.
Challenges
Citizen-generated data is not without challenges and limitations. Any data collection is naturally limited in scope and scale. Citizen-led data collection tends to focus on a smaller set of issues, is conducted in a limited geographic area like a city, or involves only individuals of specific groups. Another constraint is that citizen-generated data cannot easily be joined with other data sets, as it is designed for the purpose at hand and is often incompatible with the standards of official data collection. Finally, like all participatory processes, empowering citizens to collect, analyze, and disseminate their own data takes time and resources to build capacity, develop relationships, and compensate those shouldering the work. Insufficient long-term support or a failure to realize benefits for those involved can quickly lead to a loss of momentum and volunteer fatigue. Citizen-generated data is best thought of as a necessary complementary effort that can reveal gaps and inadequacies in the data used to support marginalized groups, highlight misconceptions, and provide a more holistic picture of the situation of those left behind.
None of these challenges is insurmountable, but overcoming them requires a coordinated approach by different stakeholders. For example, governments can adopt regulations that create a data ecosystem that supports citizen-generated data and recognizes its legitimacy as a separate but equally important source of information for decision making. National statistical offices can support the ecosystem by acting not only as data stewards but also as partners for organizations collecting data by providing technical support and ensuring that data and its benefits are owned by the organization. Governments and donors should invest in the capacity of people and their organizations to collect and use data. Enhanced data literacy and engagement will create tangible benefits for marginalized groups while boosting the ability of people to engage in the overall implementation of the Sustainable Development Goals.
The Bern Data Compact for the Decade of Action on the SDGs, adopted at the 2021 World Data Forum, includes a strong call to build trust in data by investing in rich data ecosystems and strengthening the role of all data stakeholders. Citizen-generated data is an essential part of those ecosystems to ensure that no one is left behind.
You might also be interested in
What Is Alternative Data and How Can It Help Efforts to Leave No One Behind?
Official statistics and measures of poverty do not fully capture the causes of marginalization and how they intersect and interact. The 2030 Agenda is catalyzing a shift in how the world thinks about data and the use of "non-official data sources" to better reflect the needs of the most marginalized.
Disparities in COVID Impacts Underline the Importance of Racialized Data to Understand and Address Systemic Racism
Racialized data on risk exposure and health impacts can help understand inequities in COVID-19 impact and support preventive policy decisions, but collection to date is haphazard.
Not Just Who, But Where: The need for geospatial data to achieve the Sustainable Development Goals
To advance the 2030 Agenda, the availability of geospatial data allows us to know where marginalized people are located and make the evidence-based decisions required to make sure they are no longer left behind.
Leveraging the Linkages: How human rights data can advance SDG monitoring
To create opportunities for synergies between the "leave no one behind" principle and the "realize human rights for all" principle in implementation and improved monitoring, there is a need to properly leverage data and legal mechanisms.