
Les données générées par les citoyens: des données par des personnes, pour des personnes
Les investissements dans un écosystème de données riche, qui prend en charge les données générées par les citoyens parallèlement aux sources de données officielles, renforcent l'autonomie des groupes marginalisés, permettent une compréhension holistique de la marginalisation et favorisent la prise de décision inclusive afin de garantir que personne n'est laissé pour compte dans la mise en œuvre des ODD.
Un défi majeur dans la mise en œuvre du principe du Programme 2030 de répondre aux besoins de ceux qui ont été laissés pour compte est que leurs points de vue et leurs valeurs ne sont pas correctement reflétés dans les données officielles collectées par les bureaux nationaux de statistique. Les personnes laissées pour compte souffrent également de la marginalisation des données, certains groupes étant carrément invisibles dans les statistiques nationales. Des données générées par les citoyens peuvent venir compléter les données officielles et fournir un cadre important aux décideurs. Les investissements dans un riche écosystème de données qui prenne en charge les données générées par les citoyens aux côtés des sources de données officielles renforcent les groupes marginalisés, fournissent une compréhension holistique de la marginalisation et soutiennent une prise de décision inclusive garantissant que personne ne soit laissé pour compte dans la mise en œuvre des ODD.
Qu'est-ce que des données générées par les citoyens ?
En termes simples, les données générées par les citoyens sont des « données générées par des personnes, pour des personnes », ce qui signifie que les personnes susceptibles de bénéficier de la collecte de données sont directement impliquées dans la conception, la collecte, l'analyse et l'utilisation des données qui les décrivent. Le programme CIVICUS DataShift définit les données générées par les citoyens comme étant des données que « les personnes ou leurs organisations produisent pour surveiller, exiger ou conduire directement des changements sur les problèmes qui les touchent. Il est activement donné par les citoyens, fournissant des représentations directes de leurs points de vue et une alternative aux ensembles de données collectés par les gouvernements ou les institutions internationales. Les données générées par les citoyens comprennent une grande variété d'approches et de méthodes. Selon l'objectif recherché, le terme est utilisé de manière interchangeable avec des concepts tels que Science citoyenne, Données communautaires ou Données participatives.
Le point commun à tous ces termes est que les personnes jouent un rôle actif dans une ou plusieurs étapes de la chaîne de valeur des données, depuis l'identification des questions et des objectifs jusqu'à l’élaboration des méthodes, à la collecte et à l'analyse des données et à la diffusion des résultats.
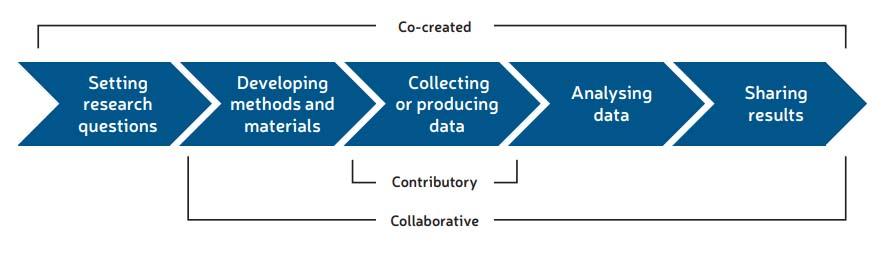
Dans leur étude de 2012, Shirk et al. distinguent les données contributives, collaboratives et co-créées en fonction de l'ampleur de l'engagement citoyen à différentes étapes. D'autres formes d'engagement partiel sont également possibles, par exemple des consultations pour déterminer l'analyse et l'interprétation des ensembles de données collectées par des sources officielles, offrant ainsi aux personnes la possibilité d'influencer et de corriger les messages véhiculés par les données en question.
Pourquoi les données générées par les citoyens sont-elles nécessaires ?
L'Institut universitaire des Nations Unies sur l'informatique et la société (UNU-CS) identifie cinq types de marginalisation des données qui peuvent exclure les voix des groupes marginalisés dans la collecte de données et la prise de décision. Comme les facteurs causant la marginalisation, les facteurs d'exclusion des données peuvent se croiser de sorte que la voix d'un groupe peut être absente des ensembles de données officiels pour de multiples raisons.
| Les voix inconnues | Ils sont des groupes de population qui sont inconnus des institutions qui collectent les données. Ces groupes comprennent des communautés isolées et intactes, des esclaves modernes, tels que des victimes du travail forcé, de la traite des êtres humains et des esclaves sexuels, et des individus qui se cachent parce qu'ils sont des immigrants illégaux, ont peur de perdre l'aide ou sont impliqués dans des activités criminelles. |
| Les voix silencieuses | Ils sont celles qui ne sont pas en mesure de participer à la collecte de données ou à d'autres activités par lesquelles leurs préoccupations pourraient être entendues. Alors que leur bien-être objectif peut être documenté, leur expérience vécue reste cachée. Les voix silencieuses incluent les personnes faibles et vulnérables en raison de leur statut socio-économique ou de leur vieillesse, les personnes handicapées et les enfants. |
| Les voix sourdes | Ils sont des groupes de population qui sont marginalisés en raison des normes sociales, des valeurs et des pratiques sociétales. Les informations sur leur bien-être sont supprimées par des moyens structurels comme l’absence de questions et de catégories dans les questionnaires ou l'exclusion de la vie sociale active. Parmi les voix sourdes figurent des membres de la communauté LGTBQ2S+, des femmes, des groupes stigmatisés confrontés aux préjugés et au racisme, ainsi que des travailleurs migrants et des réfugiés peu qualifiés. |
| Les voix inaudibles | Ils sont des groupes qui sont exclus des approches d'échantillonnage et des efforts de collecte de données parce qu'ils sont difficiles à atteindre ou difficiles à impliquer. Les voix inaudibles incluent les personnes analphabètes, qui n'ont pas d'adresse permanente, qui n'ont pas de connexion numérique, qui connaissent des limitations linguistiques ou qui ne participent pas à des activités utilisées pour générer des données, telles que l'utilisation du téléphone portable, les opérations bancaires ou l’émission de déclarations de revenus |
| Les voix ignorées | Ils sont des personnes dont les préoccupations sont perdues en raison des lacunes des méthodes statistiques, telles que le biais d'agrégation ou l'erreur écologique - en supposant que les corrélations au niveau agrégé sont vraies pour les individus - conduisant à un mépris ou à une fausse représentation du bien-être de ces personnes. |
Figure 2: Marginalisation des données (Source: Université des Nations Unies – Informatique et société, 2018)
Les données ne sont jamais parfaites. Les lacunes en matière de données et les difficultés à décrire correctement les besoins, les points de vue et les valeurs des personnes sont plus répandues au sujet des personnes marginalisées qu’à celui des autres groupes, en partie parce que la marginalisation découle d'une interaction complexe de nombreux facteurs, dont certains affectent également la collecte de données (voir encadré).
Les causes de l'exclusion de données varient d'un pays à l'autre en fonction de leur statut économique et de leur culture, mais il est juste de dire que les groupes marginalisés dans tous les pays ont du mal à faire entendre leur voix. D'un autre côté, les décideurs manquent d'informations adéquates pour concevoir des interventions efficaces. La marginalisation de données, quelle qu'elles soient, signifie que même des stratégies et des programmes bien intentionnés risquent d'être, au mieux, inefficaces et, au pire, de créer des effets néfastes, tels qu'infliger des dommages ou renforcer la stigmatisation.
Les données générées par les citoyens en action
Les données générées par les citoyens comprennent de nombreuses méthodes et approches, comme le montrent les exemples suivants. Dans chaque cas, les données ont été collectées dans un but précis qui a déterminé le processus, la manière dont les personnes se sont engagées et, finalement, le résultat obtenu.
Au Canada, de nombreuses communautés participent à Tout le monde compte, une enquête communautaire sur l'itinérance hébergée et non hébergée menée un jour précis (point dans le temps), appelée également recensement de rue. La collecte de données est menée par des bénévoles formés de la communauté à l'aide d'une enveloppe d'outils et d'une norme fournies par Emploi et Développement social Canada (EDSC) dans le cadre de la Stratégie canadienne de lutte contre l’itinérance. Les données recueillies sont utilisées pour déterminer les besoins de la communauté en matière d'abris et de logements et pour établir un lien direct avec les personnes touchées. À Winnipeg, par exemple, un recensement des rues a été effectué en 2015, 2018, 2021 et 2022. L'initiative End Homelessness Winnipeg utilise les données du recensement des rues pour suivre les progrès de son plan décennal visant à mettre fin à l'itinérance à Winnipeg. Certaines des données sont également disponibles sur Peg, le tableau de bord des indicateurs communautaires de Winnipeg.
Making Voices Heard and Count est une initiative mondiale du Centre international de la société civile qui promeut l'utilisation de données communautaires pour donner une voix et une institution aux groupes marginalisés qui risquent d'être exclus des données officielles. Les coalitions nationales d'organisations de la société civile et d'autres acteurs utilisent diverses méthodes communautaires pour collecter des données sur les groupes les plus marginalisés. Au Népal, par exemple, une coalition locale utilise des tableaux de bord communautaires pour collecter des données sur les jeunes femmes et les filles afin d'évaluer l'égalité des sexes. En Inde, des organisations de la société civile ont formé des milliers de volontaires pour collecter des données communautaires sur 20 groupes marginalisés à travers le pays.
La cartographie des rues ouverte permet aux citoyens d'annoter des cartes avec des données sur les caractéristiques physiques telles que les bâtiments et les infrastructures ainsi que des données sur l'incidence de la violence, les dommages résultant d'événements météorologiques extrêmes ou la qualité des services disponibles. L'équipe de la Humanitarian Open Street Map soutient la cartographie ouverte pour améliorer la gestion des catastrophes et réduire les risques. Le réseau IDEAMAPS (Integrated DEprived AreaMAPing) facilite la combinaison de données provenant de sources géo-spatiales, statistiques et communautaires afin d'améliorer les informations sur les habitats informels de « taudis » dans de nombreux comtés. Au Canada, Statistique Canada a utilisé la cartographie ouverte pour la collecte de données participatives sur les empreintes des bâtiments pour la Base de données ouverte des bâtiments afin de combler une lacune critique dans les données sur le logement.
Les défis
Les données générées par les citoyens ne sont pas sans défis ni limites. Toute collecte de données est naturellement limitée dans sa portée et son échelle. La collecte de données menée par les citoyens a tendance à se concentrer sur un plus petit ensemble de problèmes, est menée dans une zone géographique limitée, comme une ville, ou n'implique que des individus de groupes spécifiques. Une autre contrainte est que les données générées par les citoyens ne peuvent pas être facilement jointes à d'autres ensembles de données, car elles sont conçues pour l'objectif recherché et sont souvent incompatibles avec les normes de collecte de données officielles. Enfin, comme tous les processus participatifs, donner aux citoyens les moyens de collecter, analyser et diffuser leurs propres données prend du temps et des ressources pour le renforcement des capacités, la création des relations et la rémunération de ceux qui assument le travail. Un soutien à long terme insuffisant ou une incapacité à réaliser des avantages pour les personnes impliquées peut rapidement entraîner une perte de la dynamique et une fatigue des bénévoles. Les données générées par les citoyens sont mieux considérées comme un effort complémentaire nécessaire qui peut révéler des lacunes et des insuffisances dans les données utilisées pour soutenir les groupes marginalisés, mettre en évidence les idées fausses et fournir une image plus globale de la situation des laissés pour compte.
Aucun de ces défis n'est insurmontable, mais les surmonter nécessite une approche coordonnée des différentes parties prenantes. Par exemple, les gouvernements peuvent adopter des réglementations qui créent un écosystème de données qui prenne en charge les données générées par les citoyens et reconnaisse leur légitimité en tant que source d'informations distincte mais tout aussi importante pour le processus décisionnel. Les bureaux nationaux de statistique peuvent soutenir l'écosystème en agissant non seulement en tant que gestionnaires de données, mais en tant que partenaires des organisations qui collectent des données, en fournissant un soutien technique et en veillant à ce que les données et leurs avantages restent la propriété de l'organisation. Les gouvernements et les donateurs devraient investir dans le renforcement des capacités des personnes et de leurs organisations à collecter et à utiliser des données. L'amélioration de la maîtrise des données et de l'engagement créera des avantages tangibles pour les groupes marginalisés tout en renforçant la capacité des personnes à s'engager dans la mise en œuvre globale des ODD.
Le Pacte des données de Berne pour la décennie d’action sur les ODD, adopté lors de l’édition 2021 du Forum mondial des données, comprend un appel fort à renforcer la confiance dans les données en investissant dans des écosystèmes de données riches et en renforçant le rôle de toutes les parties prenantes des données. Les données générées par les citoyens sont un élément essentiel de ces écosystèmes pour garantir que personne ne soit laissé pour compte.
You might also be interested in
Quelles sont les données alternatives et comment peuvent-elles aider les efforts visant à ne laisser personne pour compte?
L'Agenda 2030 catalyse un changement dans la façon dont le monde pense les données et l'utilisation de "sources de données non officielles" pour mieux refléter les besoins des plus marginalisés.
Les disparités dans les impacts de la COVID soulignent l'importance des données racialisées pour comprendre et lutter contre le racisme systémique
Racialized data on risk exposure and health impacts can help understand inequities in COVID-19 impact and support preventive policy decisions, but collection to date is haphazard.
Pas seulement qui, mai où : Le besoin de données géospatiales pour atteindre les ODD
To advance the 2030 Agenda, the availability of geospatial data allows us to know where marginalized people are located and make the evidence-based decisions required to make sure they are no longer left behind.
Tirer parti des liens : Comment les données sur les droits de l'homme peuvent faire progresser le suivi des ODD
To create opportunities for synergies between the "leave no one behind" principle and the "realize human rights for all" principle in implementation and improved monitoring, there is need to properly leverage data and legal mechanisms.